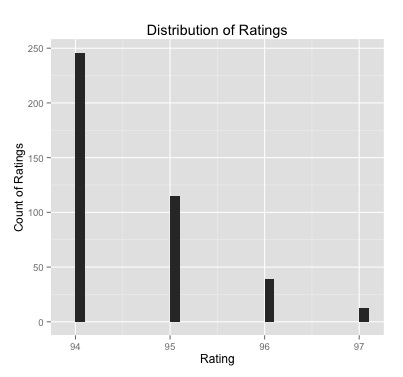
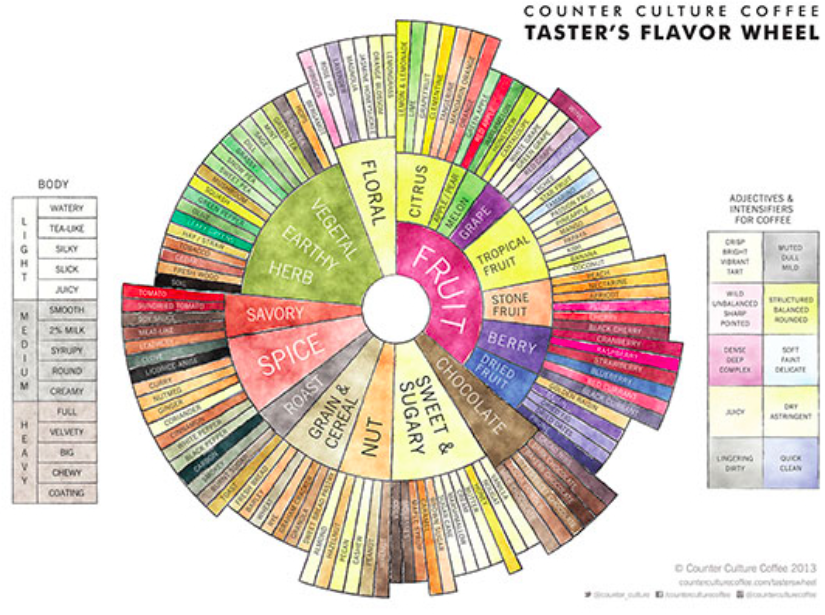
In the last post we began exploring the relationship between the language describing coffee (“cupping notes”) and price/brand/roaster. Our objective is to provide coffee consumers with a general understanding of particular groupings of coffee they can choose based on flavor profiles and mouthfeel characteristics. An example of the type of properties coffee professionals use to describe their craft is illustrated in the below flavor wheel from Counter Culture:
After evaluating the segments that our initial k-means clustering (with a k of 5) produced, I was unsatisfied with the results. My decision to haphazardly throw the price variable (unscaled) into the model was wrong-headed and drove the algorithm to essentially classify segment membership solely based upon that. In some cases such an exercise may be useful, but for our objective of discerning whether specific language could be used to segment particular specialty coffees, this segmentation wasn’t going to do it for us.
Also, this initial segmentation helped me narrow my “business objective”. Now I wanted to segment by flavor profile, something that might actually help inform a potential consumer’s purchasing decisions.
In order to develop the cupping note variables that would inform our segmentation, I explored the text data from Kenneth Davids’ site and selected the most common and/or most distinguishing words to test. The list of words is below.
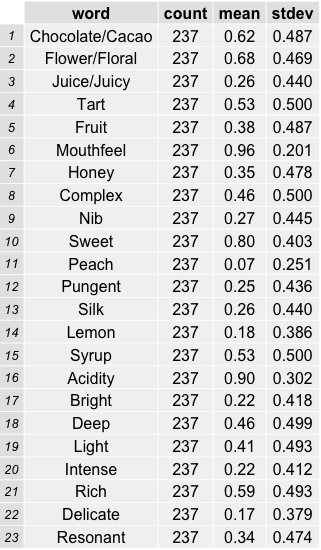
A quick look at these led me to believe that certain words might not yield significant information gain in the algorithm due to lack of variance. Mouthfeel, sweet and acidity were present in 96%, 80% and 90% of reviews respectively. Their power as differentiating variables would be constrained by their existence in nearly all observations (with the possible exception of acidity).
However, in my initial quick cluster using SPSS, I included the three variables mentioned above and I still liked the results enough to move forward.

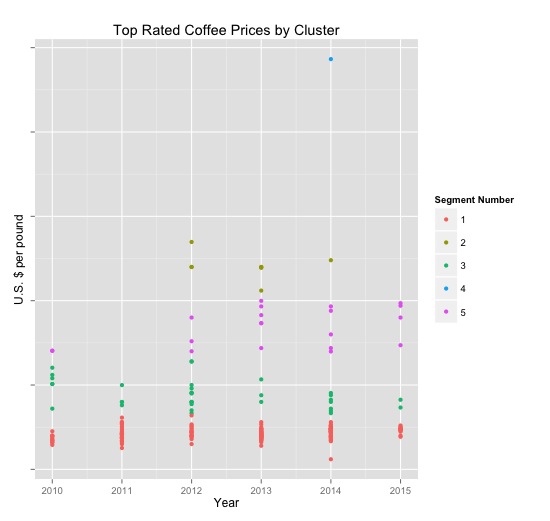
Segment 1: 16.9% of reviews
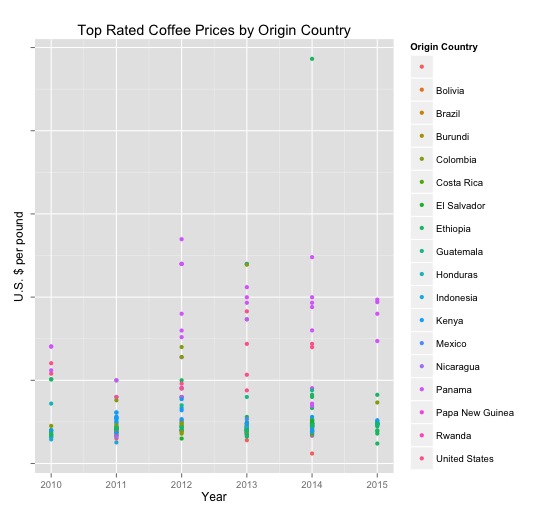
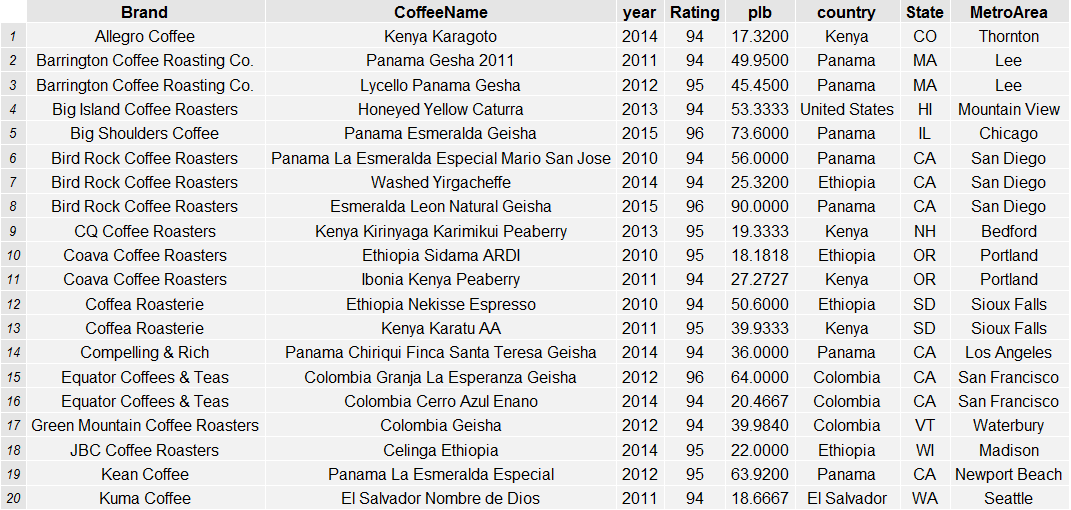
This segment was the most expensive (average $42.31 USD per pound) and highest rated (94.6). The segment was the highest indexed on floral, honey, complex, silk, delicate, intense, and peach cupping notes. It also indexed highly on nib, lemon and acidity. The most common producer countries in this mix were geisha panama and Colombia, Ethiopian, Kenyan and El Salvadoran coffees.
List of Segment One Coffees


Segment 2: 27.8% of reviews
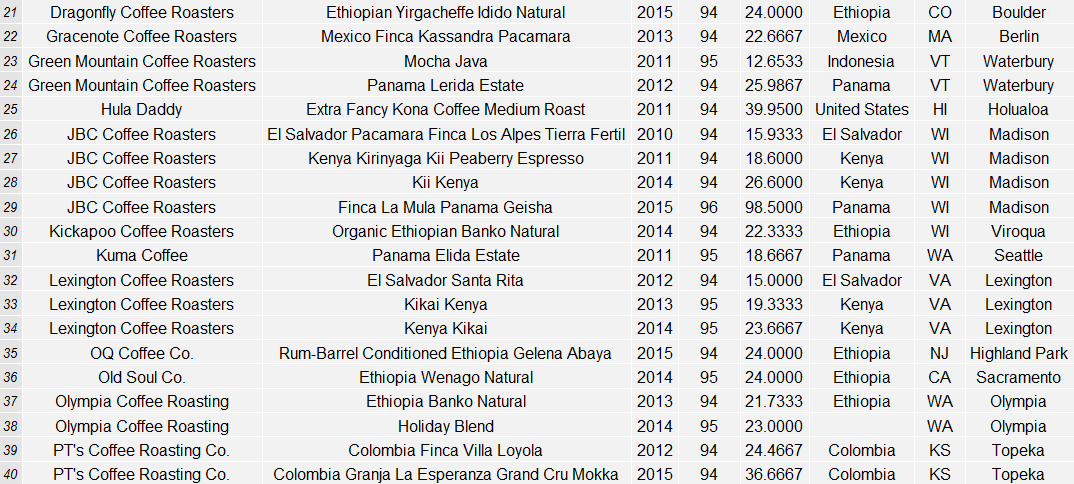
This segment was the least expensive (average $26.72 USD per pound) and moderately rated (94.45) while coming from the most diverse sampling of producer countries. It indexed highest on rich, deep, resonant and pungent cupping notes. Whereas the other segments did not include any coffees from Bolivia, Brazil, Mexico or Papa New Guinea, this segment did.
List of Segment Two Coffees

Segment 3: 13.9% of reviews
This segment was middle of the road in terms of cost and ratings (average $37.09 USD per pound and rated 94.52 on average). It indexed highest as juicy, tart, acidity, nib, bright, sweet, and was also well above average in complexity and floral notes. The range of producing countries varied quite a bit in this segment, with several bourbon varietals from Guatemala, Costa Rica, Hawaii – still other Geishas from Panama, Colombia and Guatemala – several Ethiopian Yirgacheffe coffees and a few honey processed coffees from El Salvador (Pacamara) and Hawaii (Maragogype ($75/lb)).
List of Segment Three Coffees
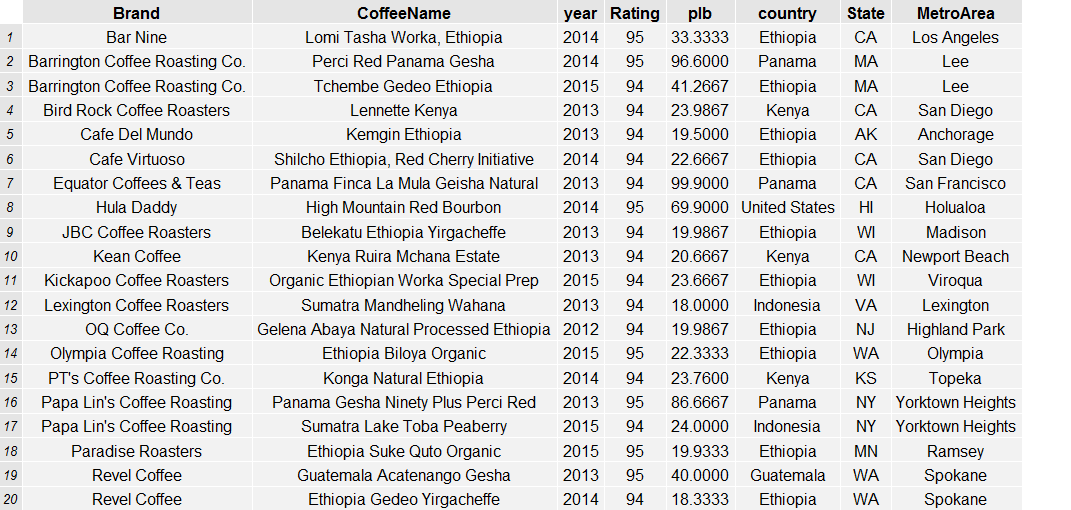

Segment 4: 20.3% of reviews
This segment was the least expensive ($28.46 USD per pound) and lowest rated (94.33) – all things relative to a very highly rated group of coffees. It indexed highest for fruit, sweet, lemon and light while also coming in pretty strong in the tart department as well. This segment is composed of a mixture of coffees from Ethiopia, Kenya, Burundi, Indonesia and Honduras. A few peaberry coffees are included, the red caturra from Rusty’s Hawaiian, a few stray Geisha coffees, and a decently heavy sampling of Sumatra, Yirgacheffe, Sidamo, and various Kenyan single-origins. For the value, this is a very attractive and diverse segment of coffees. See our site visit to Rusty’s in Hawai’i in 2011.
List of Segment Four Coffees
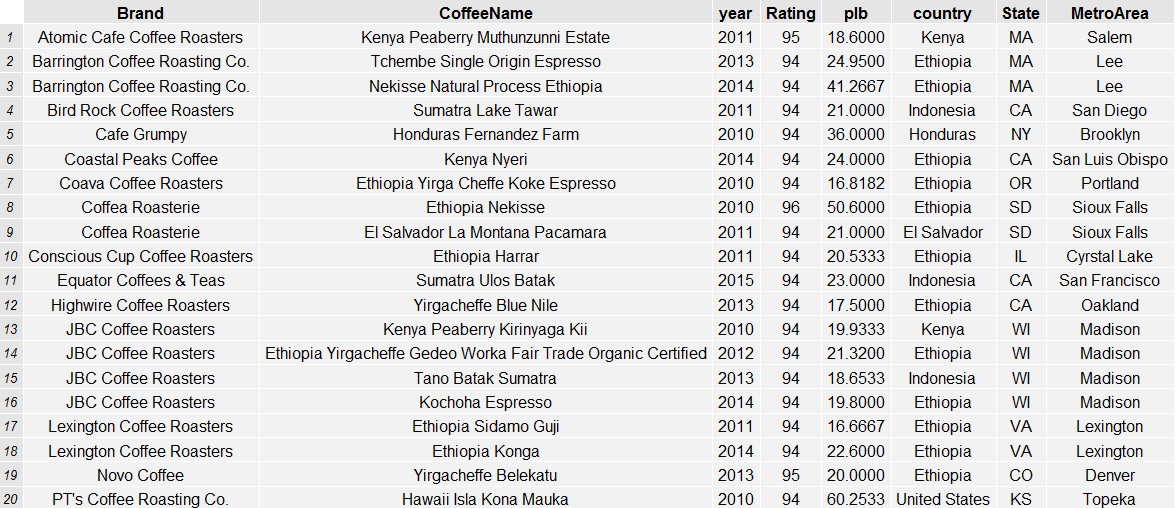
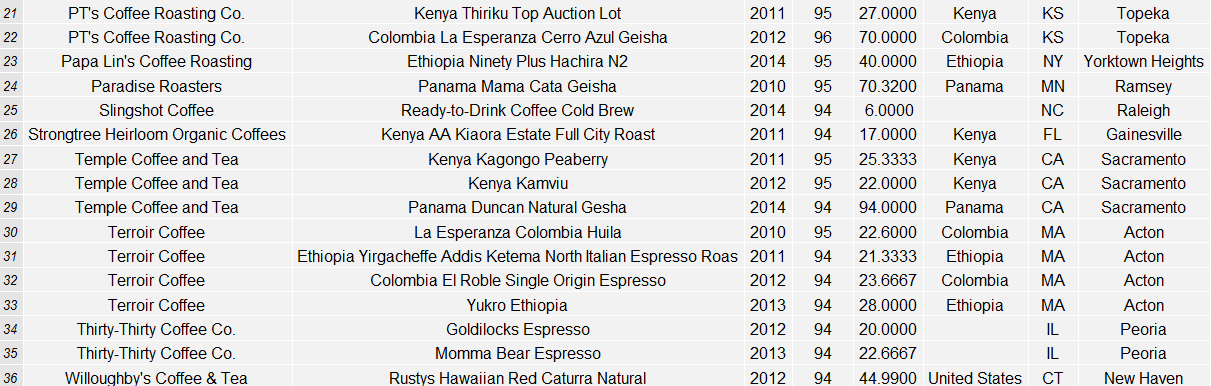

Cupping With Miguel At Lorie’s Home

Segment 5: 21.1% of reviews
Segment five is highly rated (94.58) and quite expensive ($37.73 USD per pound on average). This segment indexes the highest for tart, rich, acidity, syrup, pungent, and mouthfeel, while also scoring highly for honey and bright notes. Panama, Colombia, Hawaii and Ethiopia are the most heavily represented producer countries in this grouping. This segment is probably the most populated by Geishas followed by exotic Ethiopian and Kenyan coffees.
List of Segment Five Coffees
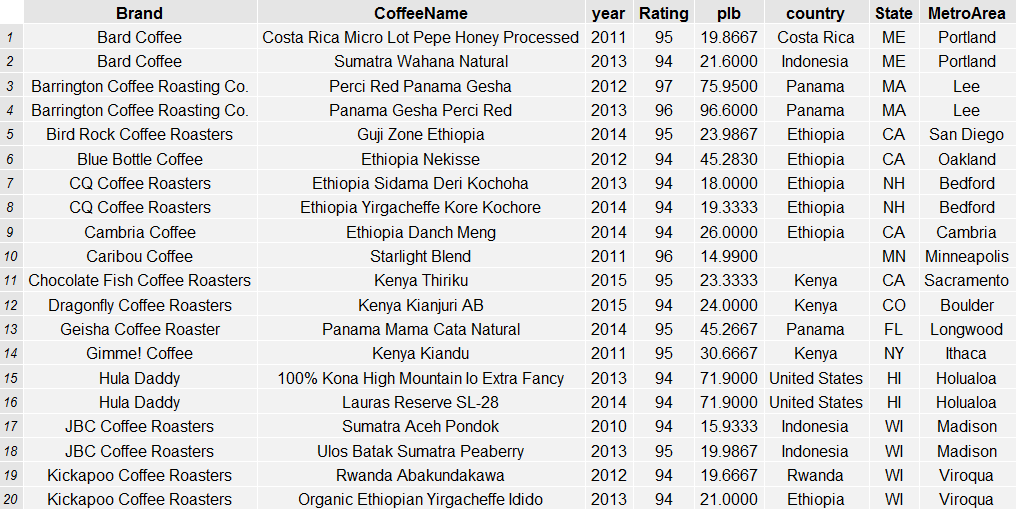
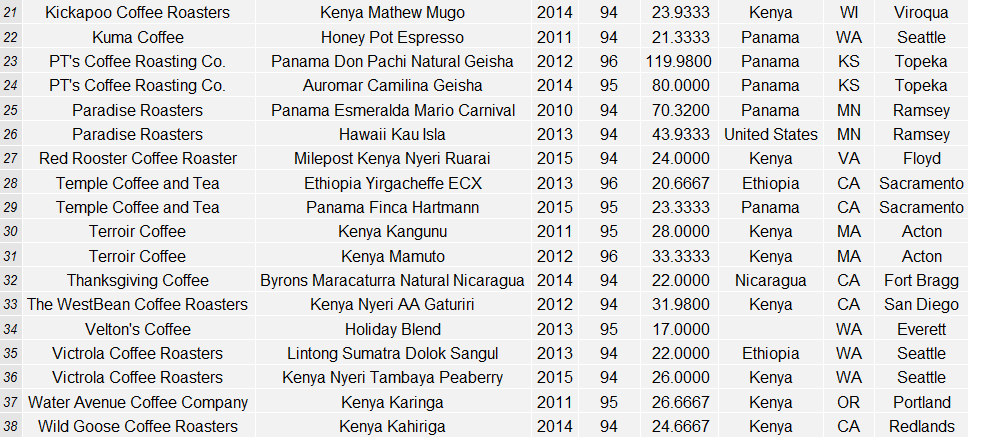
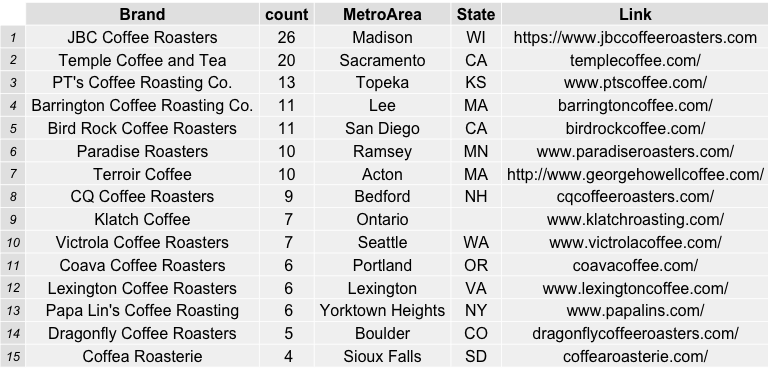
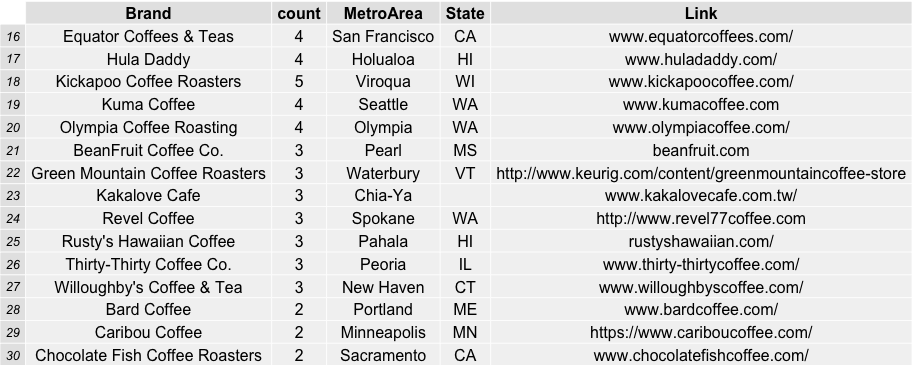
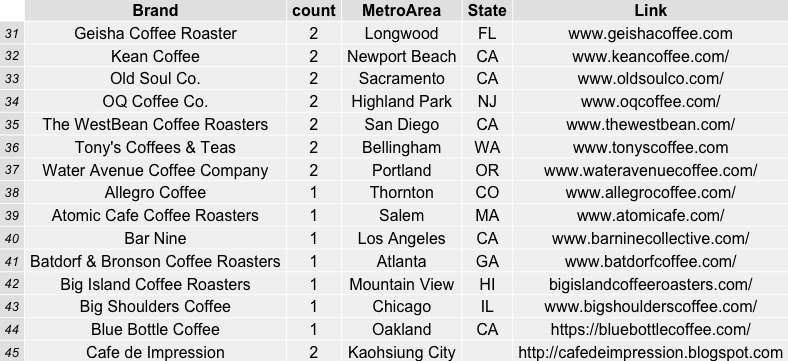
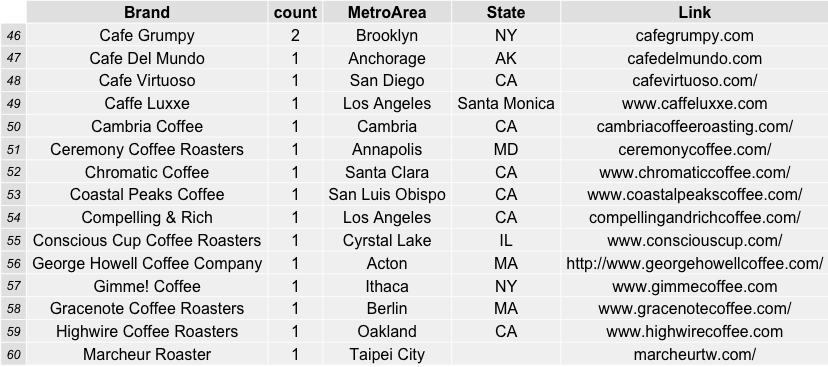
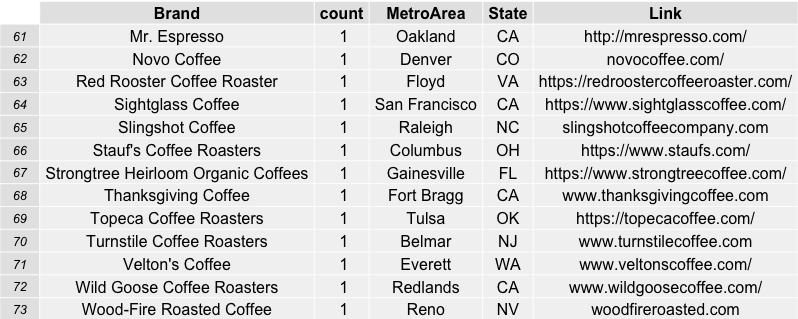
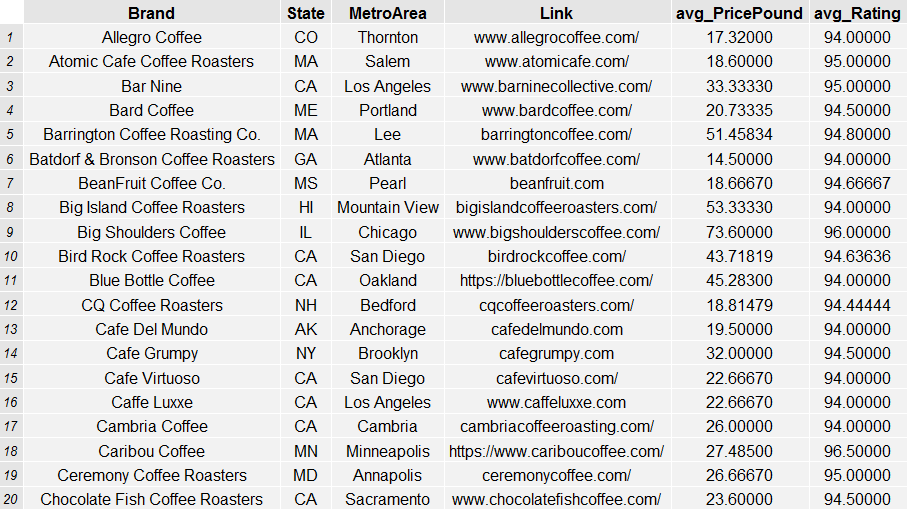
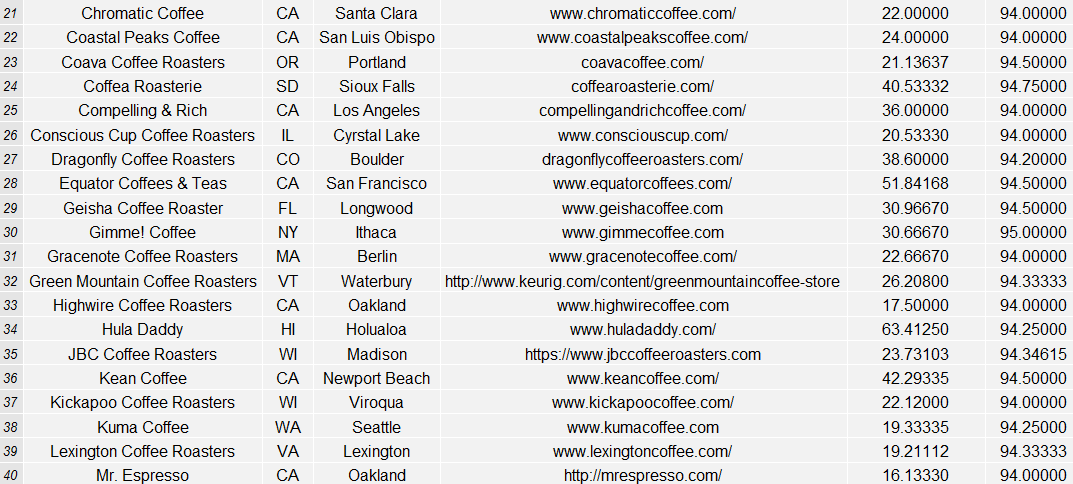
For more information on the roasters evaluated in this data from the coffeereview.com website, see the links and data below:

And I’ll leave you with a bit of a refresher on the Cup of Excellence Scoring Categories for thinking about and communicating coffee quality/taste.
Cup of Excellence® Scoring Categories
DEFECTS
Phenolic, rio, riado automatic disqualification Ferment
Oniony, sweaty
CLEAN CUP
+ purity | free from measurable faults | clarity – dirty | earthy | moldy | off-fruity
SWEETNESS (prevalence of…)
+ ripeness | sweet
– green | undeveloped | closed | tart
ACIDITY
+ lively | refined | firm | soft | having spine | crisp | structure | racy – sharp | hard | thin | dull | acetic | sour | flabby | biting
MOUTHFEEL (texture, viscosity, sediment, weight, astringency)
+ buttery | creamy | round | smooth | cradling | rich | velvety | tightly knit – astringent | rough | watery | thin | light | gritty
FLAVOR (nose + taste)
+ character | intensity | distinctiveness | pleasure | simple-complex | depth
(possible notations: nutty, chocolate, berry, fruit, caramel, floral, beefy, spicy, honey, smokey…)
– insipid | potato | peas | grassy | woody | bitter-salty-sour | gamey | baggy
AFTERTASTE
+ sweet | cleanly disappearing | pleasantly lingering
– bitter | harsh | astringent | cloying | dirty | unpleasant | metallic
BALANCE
+ harmony | equilibrium | stable-consistent (from hot to cold) | structure | tuning | acidity-body – hollow | excessive | aggressive | inconsistent change in character
OVERALL (not a correction!)
+ complexity | dimension | uniformity | richness | (transformation from hot to cold…) – simplistic | boring | do not like!